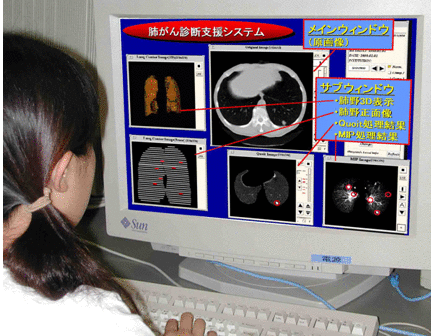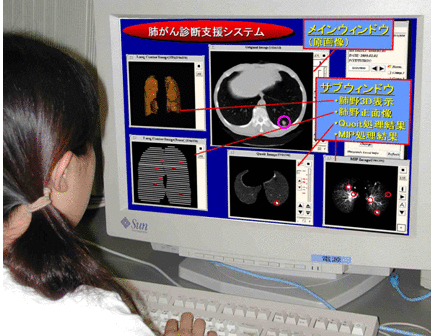
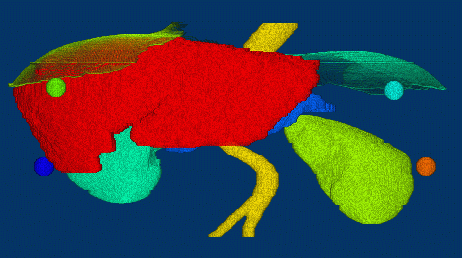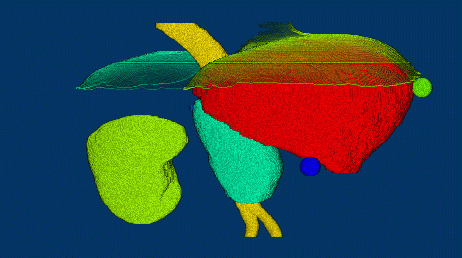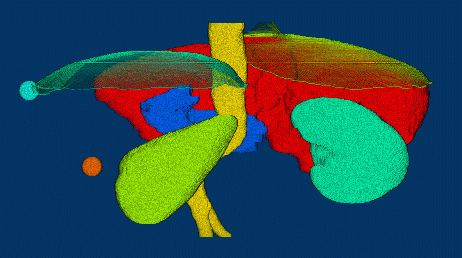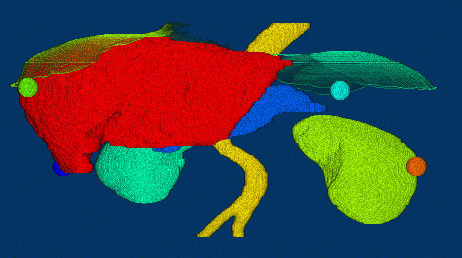
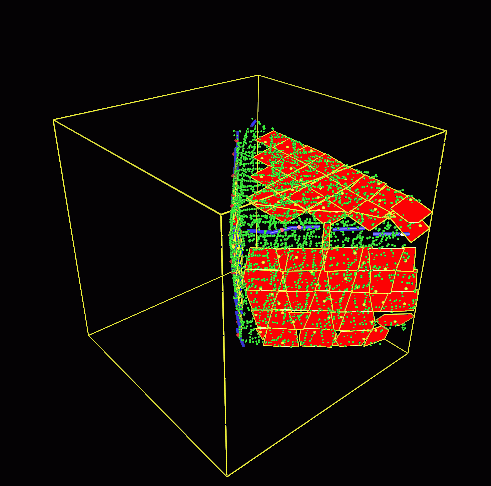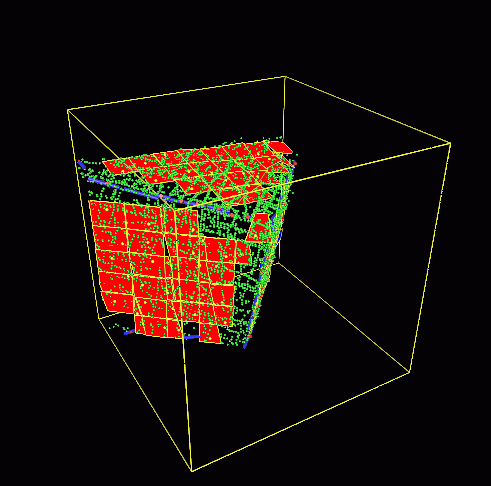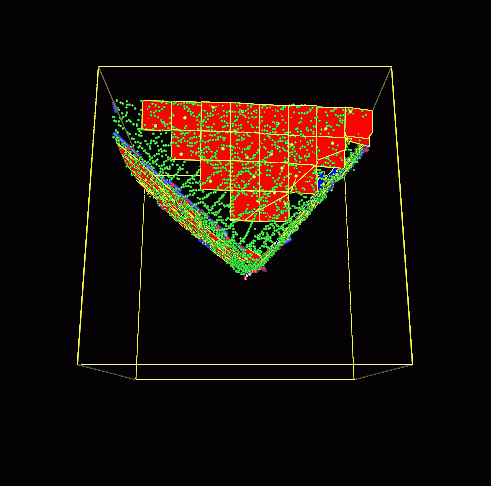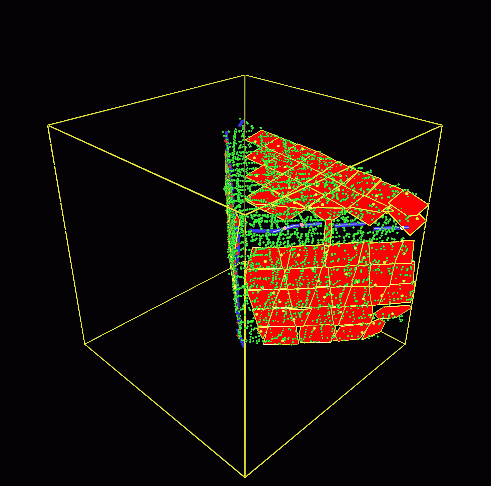
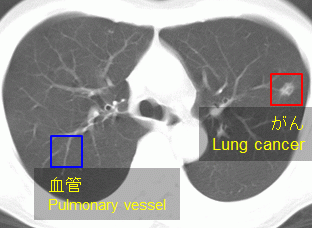
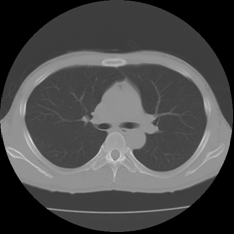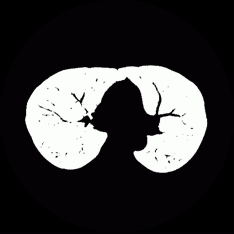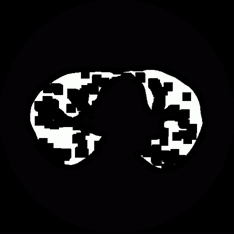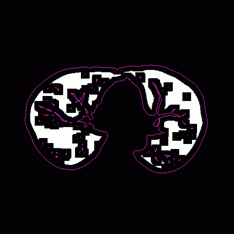
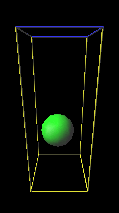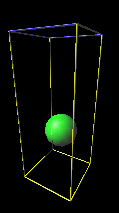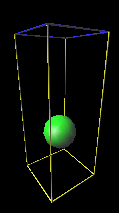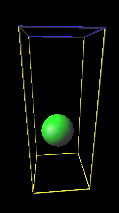
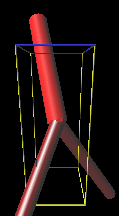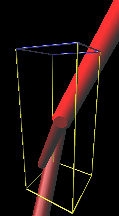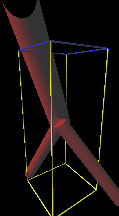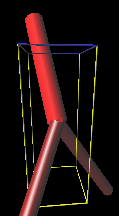
研究概要
「百聞は一見に如かず」という諺にもあるように,人間は外界情報の多くを「視 覚」から得ていると言われています.情景や物体を「見る」こと によって,その広がり,大きさ,形,色,模様などを知ることができます. コンピュータが人間のように物を見て,それが何であるか分かるようになっ たとき,コンピュータは今よりもっと賢く,柔軟性に富み,私たちの生活を さらに便利にしてくれるツールになり得ると考えられます.
筑波大学 知的画像処理研究室 では,この 「『物を見て知る』能力をコンピュー タに創り込む」ことを目指し,デジタル画像からそこに写っている 情景や物体を認識・理解するための理論とアルゴリズムの構築,ならびにそれ を実現するプログラムの開発を行っています.具体的には以下の各項目につい て研究をすすめています.